
在新建发布模块的时候,可以看到左侧有标题、正文、分类目录等信息,这个时候将采集的字段填写到右侧的内容框即可。在没有新增自定义的采集字段的时候都可以使用默认发布模块,默认发布模块只保证标题,正文有值即可发布。
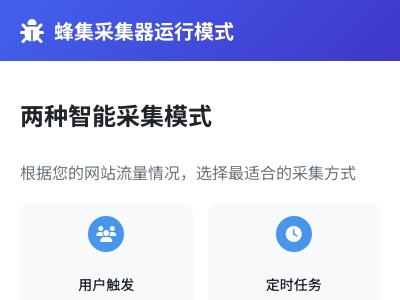
采集器的运行模式有两种:用户触发和定时任务(进入蜂集-系统配置-系统设置即可看到运行模式)。定时任务如果您安装了主机面板,设置定时任务十分方便,那么我们更推荐您使用定时任务模式。

的元素.class$(".intro")所有。visible")所有可见的表格s1,s2,s3$("th,td,.intro")所有带有匹配选择的元素$("")所有带有。

举个例子比如这个网页下面存在很多标签,在没有替换之前,抓取的结果是这样的这里的空格是可以替换的,在替换器的左侧输入一个空格,右侧输入半角逗号即可将空格替换成逗号。
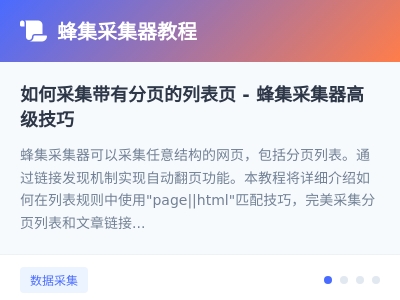
首先我们需要找到分页链接和其他链接不一样的地方,例子中的分页的链接都有“page”这个单词而其他的链接都没有这个单词,那么我们在列表规则中的链接包含框填上“page”,这样就可以采集到所有的翻页链接,如下图:填写完了之后,我们将测试的链接填入到文章测试地址中进行测试抓取,结果如下图:可以发现,我们已经完美匹配到了分页链接。

为例子,点击开发者工具中的小箭头,如下图:然后鼠标放到网页中寻找需要采集的区域,在右侧中对应的源代码会被高量显示,如下图所示:因此我们左侧选中的区域的class就是content,写成xpath如下:意思就是匹配根结点下面任意class名称为content内容。
如下图:现在我们可以建立一个简单的采集任务,我们现在可以采集一个新闻网站。现在可以添加任务,采集模块和发布模块选择我们刚才建立的模块,如下图:填写完毕之后,点击提交即可。

比如我们使用首页测试一下抓取,可以看到下面抓取了很多链接我们再用内部文章页面测试抓取,可以看到下面依然有新的链接第二步:设置正文规则如果你懂XPath或者正则,那么写一个抓取正文的规则是一件很容易的事情。

如何开启进程模式第一步:进入蜂集后台,找到系统配置,运行模式选择进程模式第二步:打开WP扩展,找到系统配置-进程,点击开启进程即可(下面是是进程已经启动的情况)当前的进程在windows和linux上均可使用,不过windows上没有测试,可能会存在一些问题,如果有问题的话请先停止进程并且将蜂集的采集模式改回用户触发,然后向作者反馈。

XPath的方便之处就在于可以用浏览器直接提取出来。如何用浏览器提取XPath使用chrome浏览器打开你想采集的网址。XPath来代替copy。测试XPath把提取到的XPath复制到规则中点击测试抓取由于有些占站点做了防盗链,直接采集时候可能图片不会展示,不过采集下来的时候,图片会自动本地化,此时图片可以展示。

设定作用任务名称为任务设置一个名字入口URL采集插件抓取的第一个网页,也就是采集入口采集模块这个任务都会使用这里绑定的采集模块去采集发布模块这个任务都会使用这里绑定的发布模块去发布文章发布状态设置这个任务下的文章发布时候的发布状态添加任务完成之后,我们就可以返回任务列表,首先手动执行一次,看看任务是不是能够正常跑起来。

测试采集当所有的规则都编写完毕之后,我们需要验证一下采集器是不是可以根据该规则正确采集,进入测试抓取Tab,填写链接和页面层级,点击抓取测试,查看效果,如下图:如果对采集器有使用上的疑惑,可以到蜂集采集交流群(群号在采集器的关于我们中可以找到)进行交流。