
你是不是也遇到过这种情况——WordPress 网站里莫名其妙多出来好多重复的文章?这些重复内容不仅让读者看着 […]

wpnovo是一款专为小说网站设计的WordPress主题,支持多语言功能,适合面向全球用户的小说站长。其多语言机制基于WordPress多站点功能,允许为每种语言创建独立的子站点,同时保持统一的主题风格和功能,便于管理不同语言版本的内容。配置步骤包括:首先开启WordPress多站点功能,登录后台访问“工具”→“网络设置”,完成配置并修改相关文件;然后在wpnovo主题设置面板的“多语言切换”选项卡中勾选需要启用的语言,并为当前站点选择对应语言(如主站选择中文)。

在AI时代,伪原创通过智能优化提升文章质量,使其更清晰、更符合读者需求。本教程详细介绍了使用AI工具箱进行伪原创的步骤:首先设置模型并选择如GPT-4.1等主流模型,确保API Key已配置;其次进行单篇文章处理,选择正文伪原创并等待生成新版本;最后通过批量处理功能优化历史文章,设置任务频率并监控进度。伪原创应保留原意、提升可读性、增加价值并优化结构。常见问题解答包括抄袭判定、质量评估及流量下降的应对策略,强调使用最新大模型以获得最佳效果。

AI工具箱现支持在网站前台展示SEO诊断工具,帮助用户优化SEO并引流。通过前台展示Tab获取简码,插入文章或页面即可使用。可设置用户使用次数限制(如默认5次),超出后需付费提升额度。在用户管理中调整限额,-1表示无限制。立即下载AI工具箱,利用SEO诊断功能提升网站流量和收入!

AI 工具箱 1.8.2 版本新增了 SEO 诊断功能,帮助用户快速识别网站 SEO 问题并提供解决方案。用户只需更新至最新版本,即可在工具页面使用该功能。操作简单:首先设置诊断模型,推荐使用 DeepSeek、GPT-4o 等高性能模型以获得更准确的结果(建议参数:温度 0.8,TopP 0.6)。支持诊断首页、自定义链接甚至其他网站的 SEO 表现,一键生成优化建议,助力提升搜索引擎排名。

本文回顾了作者从早期自动配图插件到AI赋能的迭代历程:初代解决图片唯一性,二代提升视觉精致度,而当前AI技术实现了质变突破。新版AI配图系统具备四大核心功能:智能生成内容相关主图、自适应平台缩略图、带二维码的营销配图及全站批量处理。通过三代技术对比图直观展示AI在表现力上的显著优势,并附详细操作指南:需先配置deepseek v3大模型,开启配图功能后1-2分钟即可生成图片,支持自动风格识别、小红书风、六宫格等多样化风格选择,正文与缩略图可独立设置风格参数。(160字)

在新建发布模块的时候,可以看到左侧有标题、正文、分类目录等信息,这个时候将采集的字段填写到右侧的内容框即可。在没有新增自定义的采集字段的时候都可以使用默认发布模块,默认发布模块只保证标题,正文有值即可发布。
采集器的运行模式有两种:用户触发和定时任务(进入蜂集-系统配置-系统设置即可看到运行模式)。定时任务如果您安装了主机面板,设置定时任务十分方便,那么我们更推荐您使用定时任务模式。

的元素.class$(".intro")所有。visible")所有可见的表格s1,s2,s3$("th,td,.intro")所有带有匹配选择的元素$("")所有带有。

举个例子比如这个网页下面存在很多标签,在没有替换之前,抓取的结果是这样的这里的空格是可以替换的,在替换器的左侧输入一个空格,右侧输入半角逗号即可将空格替换成逗号。
首先我们需要找到分页链接和其他链接不一样的地方,例子中的分页的链接都有“page”这个单词而其他的链接都没有这个单词,那么我们在列表规则中的链接包含框填上“page”,这样就可以采集到所有的翻页链接,如下图:填写完了之后,我们将测试的链接填入到文章测试地址中进行测试抓取,结果如下图:可以发现,我们已经完美匹配到了分页链接。
上面xxx一般是发布字段,后面的一串以大括号包住的内容则是条件,min_len表示该字段里面的内容最小长度,比如设置1表示采集到的长度大于1才会入库,否则就会提示发布条件不通过。

为例子,点击开发者工具中的小箭头,如下图:然后鼠标放到网页中寻找需要采集的区域,在右侧中对应的源代码会被高量显示,如下图所示:因此我们左侧选中的区域的class就是content,写成xpath如下:意思就是匹配根结点下面任意class名称为content内容。
如下图:现在我们可以建立一个简单的采集任务,我们现在可以采集一个新闻网站。现在可以添加任务,采集模块和发布模块选择我们刚才建立的模块,如下图:填写完毕之后,点击提交即可。

比如我们使用首页测试一下抓取,可以看到下面抓取了很多链接我们再用内部文章页面测试抓取,可以看到下面依然有新的链接第二步:设置正文规则如果你懂XPath或者正则,那么写一个抓取正文的规则是一件很容易的事情。
创建完之后,在右侧会出现你刚才创建的小说点击编辑,这个时候可以编辑小说一些封面,作者,介绍等信息,如下图如何创建菜单可以查看下面这篇创建菜单教程如何设置PC首页PC首页由六个区块构成,它们分别是:编辑推荐,新书推荐,分类展示(竖版),分类展示(横版),最近更新。

如何开启进程模式第一步:进入蜂集后台,找到系统配置,运行模式选择进程模式第二步:打开WP扩展,找到系统配置-进程,点击开启进程即可(下面是是进程已经启动的情况)当前的进程在windows和linux上均可使用,不过windows上没有测试,可能会存在一些问题,如果有问题的话请先停止进程并且将蜂集的采集模式改回用户触发,然后向作者反馈。

XPath的方便之处就在于可以用浏览器直接提取出来。如何用浏览器提取XPath使用chrome浏览器打开你想采集的网址。XPath来代替copy。测试XPath把提取到的XPath复制到规则中点击测试抓取由于有些占站点做了防盗链,直接采集时候可能图片不会展示,不过采集下来的时候,图片会自动本地化,此时图片可以展示。

从1.2.10版本开始,wordpress扩展集增加了一个SEO工具箱,目前支持百度推送以及一些常用搜索引擎的收录快速查看。接下来可以设置百度token,开启自动推送。如何找到百度推送token进入百度站长平台,一次点击资源提交->普通收录把箭头覆盖的一串字符即为token。

设定作用任务名称为任务设置一个名字入口URL采集插件抓取的第一个网页,也就是采集入口采集模块这个任务都会使用这里绑定的采集模块去采集发布模块这个任务都会使用这里绑定的发布模块去发布文章发布状态设置这个任务下的文章发布时候的发布状态添加任务完成之后,我们就可以返回任务列表,首先手动执行一次,看看任务是不是能够正常跑起来。

测试采集当所有的规则都编写完毕之后,我们需要验证一下采集器是不是可以根据该规则正确采集,进入测试抓取Tab,填写链接和页面层级,点击抓取测试,查看效果,如下图:如果对采集器有使用上的疑惑,可以到蜂集采集交流群(群号在采集器的关于我们中可以找到)进行交流。
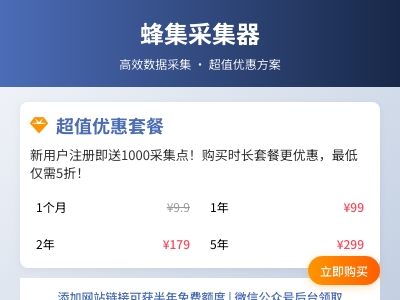
spm=a2oq0.12575281.0.0.4ace1debEFUDXU&ft=t&id=618722676249收费标准时长原价优惠价折扣1个月9.99.9无1年118.899.08折2年237.9179.07.5折3年356.4249.07折5年588.0299.05折添加连接在您的网站上添加一个指向蜂集采集器的链接,您将获得半年的使用额度,发放规则为每个月发放一次,添加连接之后,可以在微信公众号后台恢复您的站点信息,后续半年中每个月将可以免费获取额度30天的充值码一枚。

注册之后,账户信息只会显示一次,您必须保存下来,如果您遗忘了,请凭您注册时候的账号名和邮箱找管理员找回(请加群:175991304)填写账户如果您已经拥有账户,可以直接在后台填写账户,不需要重复注册。
wordpress小说主题imwpclassic。为什么文章列表点击上下移动无效如果你的章节点击上下移动无效,原因是两篇文章的发布时间是一样的,这种情况无法调整章节顺序。

imwpclassic和wpnovo主题提供了小说和章节发布接口。通过后台进入相应主题的设置页面,可以找到发布接口的查看路径。小说发布接口用于发布小说信息,包括标题、简介、作者等字段。章节发布接口用于发布小说章节,包括章节标题、内容、分类等字段。接口返回值会返回一个json格式的结果,发布成功或失败都会返回相应的信息。通过接口文档,可以制作采集器的发布模块来使用该接口。
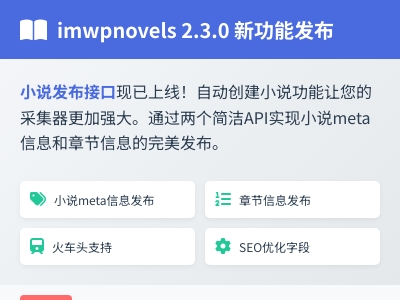
摘要:imwpnovels从2.3.0版本开始新增小说发布接口,可自动创建小说。该接口包括添加小说meta信息和章节信息两个接口。meta信息包括小说名称、封面、描述、作者等,可通过imwpapi.php?op=add_novel增加。发布小说章节的接口为imwpapi.php?op=add_post。该接口支持任意支持接口发布的采集器,访问地址在主题api文件夹内。发布模块包括novels和novels-section两个火车头发布模块,分别用于发布小说meta信息和章节信息。发布前需测试模块,注意章节乱序问题并调整采集和发布设置。

摘要:环境要求为PHP 5.2以上和WordPress 4.7以上才能使用IMWP系列主题,建议使用后台上传主题。通过FTP上传方式将主题文件解压后上传到wp-content/themes目录下。使用前需绑定域名,注册IMWPweb账户后,联系管理员进行域名绑定。支持绑定的域名数量由主题决定。

摘要:本文是关于WordPress单本小说主题imwpnovel的说明书,内容包括环境要求、主题安装、后台使用、注意事项和升级更新等方面的介绍。主题推荐使用php7和WordPress最新版,安装方法包括通过WordPress后台上传和通过FTP上传两种方式。建立小说分类和小说流程简单,后台管理面板可设定丰富内容,如Logo、首页推荐小说等。查找ID信息可通过安装imwpf插件并开启后台增强功能实现。
摘要:本文是关于WordPress主题imwpnovel的说明书,介绍了环境要求、安装步骤、域名绑定、后台使用及注意事项等。该主题需要PHP5.2以上和WordPress4.7以上的环境。安装方法包括通过WordPress后台上传或FTP上传。使用前需进行域名绑定,并遵循绑定过程中的错误代码提示进行调试。主题具有强大的后台管理界面,可自定义多种参数。购买者需遵守使用规定,不得倒卖主题。更新升级时,会通过邮件通知购买者。

针对WordPress用户手动配图效率低、效果差的痛点,本文推荐一款AI自动配图插件。该插件能基于文章内容智能生成风格匹配的头图和缩略图,支持小红书封面等多样式选择,并可自定义尺寸与分类适配。通过自动化的配图流程,用户可节省10-30分钟/篇的修图时间,获得比人工挑选更精准的配图效果。插件还提供分类管理、尺寸调节等功能,有效解决图片拉伸模糊问题。适用于名言、影评、教程等各类文章,显著提升内容呈现质量。开发者欢迎用户反馈优化建议。