如何使用XPath采集网页

使用XPath采集网页中的内容是一件十分简单的事情,这里介绍两种xpath的写法——使用id提取网页中的内容和使用class提取网页中的内容。
如果你看过网页源代码,那么就会发现,网页中内容一般由带有id或者class的div包围,而XPath就可以将这些被div包围着的内容全部匹配出来。因此我们可以编写特定的XPath规则来采集我们想要的内容。
如何查看HTML源代码
打开chrome浏览器,然后打开你想采集的网址,进入浏览器的开发者模式(windows为F12,macos为command+option+i)。源代码一般是如下:

根据div的class匹配
以这个页面 https://www.imwpweb.com/5437.html 为例子,点击开发者工具中的小箭头,如下图:

然后鼠标放到网页中寻找需要采集的区域,在右侧中对应的源代码会被高量显示,如下图所示:
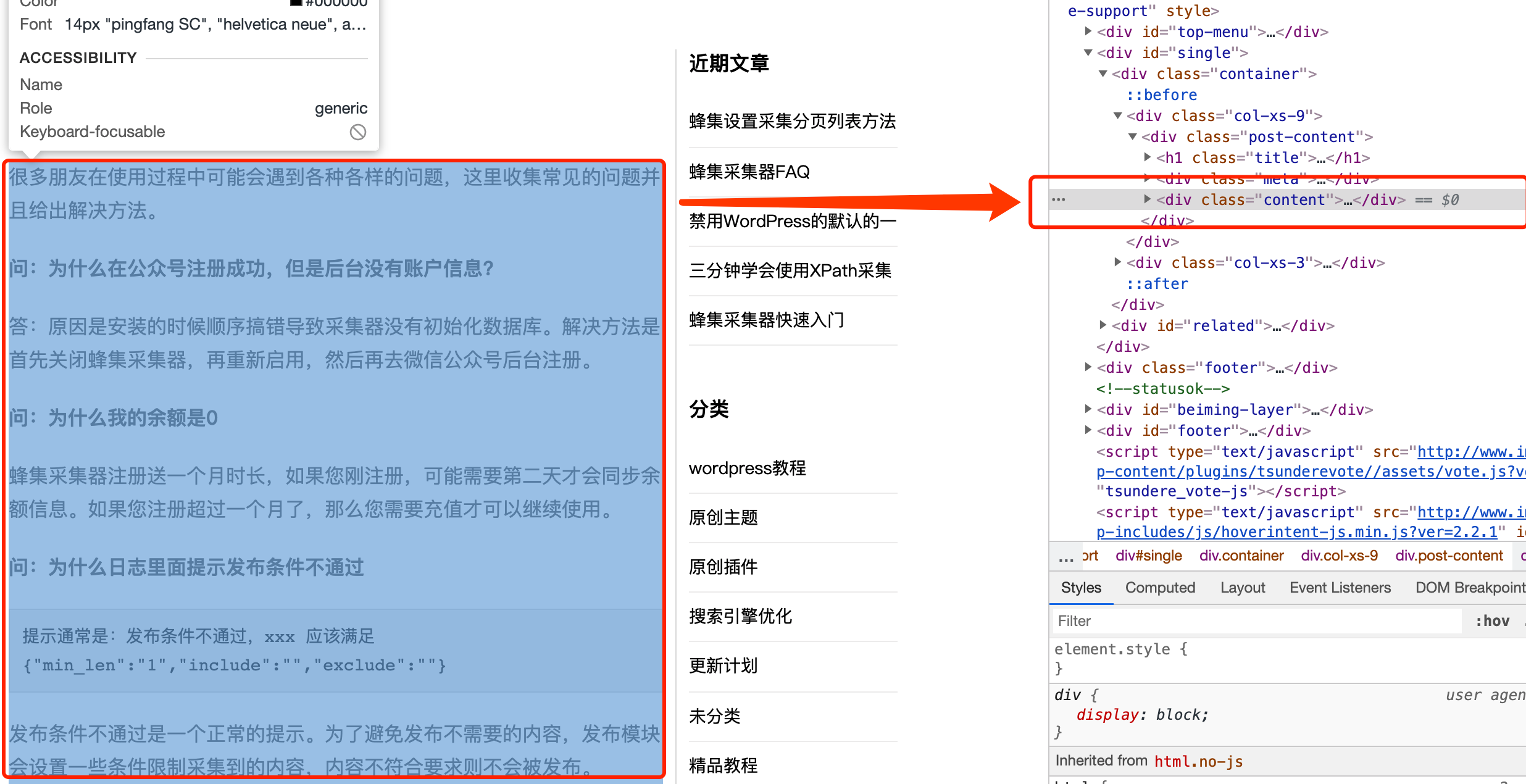
因此我们左侧选中的区域的class就是content,写成xpath如下:
//*[@class="content"]意思就是匹配根结点下面任意class名称为content内容。
如果您选中的区域的class是其他的,那么只需要把content替换成其他的就可以。
根据div的id匹配
同理,如果网页中有一个id为content的div。比如下面的相关推荐区域就是id,

那么规则应该写成:
//*[@id="relate"]看到这里,大家明白了吗?
你可能还喜欢下面这些文章

 WordPress小说主题wpnovo,支持多语言、付费阅读、VIP会员功能的精美小说模板
WordPress小说主题wpnovo,支持多语言、付费阅读、VIP会员功能的精美小说模板
//demo.imwpweb.com/wpnovo/多设备支持主题支持PC和移动端界面,独立设置,互不干扰。移动端首页(右)图:小说页面PC端和移动端的展示付费订阅主题支持付费订阅功能,支持付费单章订阅、整本小说订阅模式。
 WordPress自动内链插件 WPKAL ,网站全自动增加锚链接必备插件
WordPress自动内链插件 WPKAL ,网站全自动增加锚链接必备插件
什么是内链内链,顾名思义就是在同一网站域名下的内容页面之间的互相链接(自己网站的内容链接到自己网站的内部页面,也称之为站内链接)。自动内链工作原理简单来说,我们设定一些词表以及词表对应的链接,比如词是wordpress插件,链接是http
 WordPress 敏感词违禁词屏蔽插件 WPWJC 介绍与下载
WordPress 敏感词违禁词屏蔽插件 WPWJC 介绍与下载
这款插件的核心功能就是一点:找出文章中的违禁词、敏感词等措辞不当的词语,替换成你设置的更合适的词或者直接替换“*”号。请注意,需要同时下载站长工具箱和违禁词屏蔽插件,安装插件时也需要两个插件同时安装。
 WordPress 文章自动配图、缩略图插件 WPAC 介绍与下载
WordPress 文章自动配图、缩略图插件 WPAC 介绍与下载
2、自动生成的图片并非真实在磁盘中的图片,而是动态生成的,如果保存到磁盘会占用大量空间,这个空间没必要浪费,因此修改主题代码,直接将缩略图的地址改为wpac自动生成的缩略图地址是一个非常好的方案。
 WordPress 相关文章插件 wprec
WordPress 相关文章插件 wprec
wprec利用相似度算法计算每篇文章之间的相似度,找到与当前文章最相似的一些文章,展现在文章底部作为相关文章。我们知道,相关推荐插件推荐的原理是根据当前文章的特征(文章的高权重标签),从文章库中召回相关文章,再根据相关性评分,最后选出To